이번 챕터에서는 RNN 계열의 신경망 바닐라 RNN, LSTM, GRU를 사용하여 텍스트 분류를 실습한다.
# 10-01 바닐라 RNN으로 스팸메일 분류(이진분류)
다대일 구조의 바닐라 RNN 모델 설계
from tensorflow.keras.layers import SimpleRNN, Embedding, Dense
from tensorflow.keras.models import Sequential
embedding_dim = 32 # 임베딩백터 차원
hidden_units = 32 # 은닉상태 크기
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(SimpleRNN(hidden_units))
model.add(Dense(1, activation='sigmoid')) # 이진분류
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train_padded, y_train, epochs=4, batch_size=64, validation_split=0.2)
# 검증데이터=과적합확인용
테스트 데이터에 대해 모델 평가
X_test_encoded = tokenizer.texts_to_sequences(X_test)
X_test_padded = pad_sequences(X_test_encoded, maxlen = max_len)
print("\n 테스트 정확도: %.4f" % (model.evaluate(X_test_padded, y_test)[1])) # 0.9821
훈련 데이터와 검증 데이터의 정확도 시각화
epochs = range(1, len(history.history['acc']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()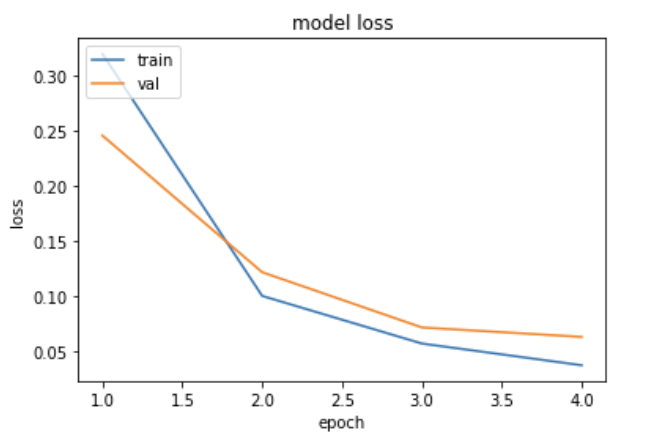
# 10-02 LSTM으로 로이터뉴스 분류(다중클래스 분류)
데이터 준비
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.models import load_model
vocab_size = 1000 # 빈도수 상위 1000개 단어만 사용
max_len = 100 # 모든 뉴스기사 길이 100으로 패딩
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=vocab_size, test_split=0.2)
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
# 레이블에 원핫인코딩
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
다대일 구조의 LSTM 모델 설계
embedding_dim = 128 # 임베딩벡터 차원
hidden_units = 128 # 은닉상태 크기
num_classes = 46 # 다중클래스 레이블 개수
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(LSTM(hidden_units))
model.add(Dense(num_classes, activation='softmax')) # 다중클래스 분류
# 검증데이터 손실(val_loss)이 증가하면 과적합 징후이므로 4회 증가하면 학습 조기종료
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
# 검증데이터 정확도(val_acc)이 전보다 좋아질 경우에만 모델 저장
mc = ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
history = model.fit(X_train, y_train, batch_size=128, epochs=30, callbacks=[es, mc], validation_data=(X_test, y_test))
테스트 데이터에 대해 모델 평가
loaded_model = load_model('best_model.h5') # 훈련 과정에서 검증데이터가 가장 높았던 모델
print("\n 테스트 정확도: %.4f" % (loaded_model.evaluate(X_test, y_test)[1])) # 0.7124
훈련 데이터와 검증 데이터의 정확도 시각화
epochs = range(1, len(history.history['acc']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()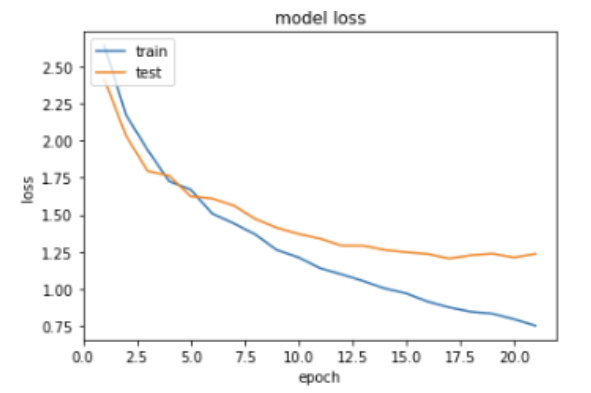
# 10-03 GRU로 IMDB 리뷰 감성분류(이진분류)
데이터 준비
import re
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, GRU, Embedding
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.models import load_model
vocab_size = 10000 # 단어집합 크기 제한
max_len = 500 # 리뷰 최대길이 제한
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=vocab_size)
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
다대일 구조의 GRU 모델 설계
embedding_dim = 100 # 임베딩벡터 차원
hidden_units = 128 # 은닉상태 크기
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(GRU(hidden_units))
model.add(Dense(1, activation='sigmoid')) # 이진분류
# 검증데이터 손실이 4회 증가하면 학습을 조기종료
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
# 검증데이터 정확도가 이전보다 좋아질 경우에만 모델 저장
mc = ModelCheckpoint('GRU_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train, y_train, epochs=15, callbacks=[es, mc], batch_size=64, validation_split=0.2)
테스트 데이터에 대해 모델 평가
loaded_model = load_model('GRU_model.h5')
print("\n 테스트 정확도: %.4f" % (loaded_model.evaluate(X_test, y_test)[1])) # 0.8893
입력된 문장에 대해 기본 전처리, 정수 인코딩, 패딩을 진행해 리턴하는 함수 정의
def sentiment_predict(new_sentence):
# 소문자
new_sentence = re.sub('[^0-9a-zA-Z ]', '', new_sentence).lower()
encoded = []
# 띄어쓰기 단위 토큰화 후 정수 인코딩
for word in new_sentence.split():
try :
# 단어 집합의 크기를 10,000으로 제한
if word_to_index[word] <= 10000:
encoded.append(word_to_index[word]+3)
else:
# 10,000 이상의 숫자는 <unk> 토큰으로 변환
encoded.append(2)
# 단어 집합에 없는 단어는 <unk> 토큰으로 변환
except KeyError:
encoded.append(2)
pad_sequence = pad_sequences([encoded], maxlen=max_len)
score = float(loaded_model.predict(pad_sequence)) # 예측
if(score > 0.5):
print("{:.2f}% 확률로 긍정 리뷰입니다.".format(score * 100))
else:
print("{:.2f}% 확률로 부정 리뷰입니다.".format((1 - score) * 100))
결과 확인
test_input = "This movie was just way too overrated. The fighting was not professional and in slow motion. I was expecting more from a 200 million budget movie. The little sister of T.Challa was just trying too hard to be funny. The story was really dumb as well. Don't watch this movie if you are going because others say its great unless you are a Black Panther fan or Marvels fan."
sentiment_predict(test_input)
# 97.43% 확률로 부정 리뷰입니다.
# 10-04 Naive Bayes Classifier
(1) 베이즈의 정리
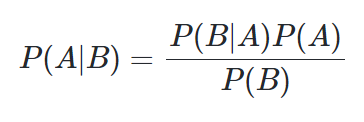
즉, 나이브 베이즈 분류기는 오직 빈도수만을 고려하기 때문에 토큰화 이전의 단어의 순서가 중요하지 않음.
(2) 스팸메일 분류

" you free lottery " 가 정상메일일 확률과 스팸메일일 확률을 구해본다.
P(정상메일 | you free lottery) = P(you | 정상메일) X P(free | 정상메일) X P(lottery | 정상메일) = 2/10 x 2/10 x 0/10 = 0
P(스팸메일 | you free lottery) = P(you | 스팸메일) X P(free | 스팸메일) X P(lottery | 스팸메일) = 2/10 x 3/10 x 2/10 = 0.012
정상메일일 확률 < 스팸메일일 확률이므로 "you free lottery"는 스팸메일로 분류된다.
그러나 정상메일에 lottery가 등장하지 않았다고 해서 정상메일일 확률이 0%가 되어버리는 것은 지나친 일반화
따라서 나이브베이즈 분류기는 "라플라스 스무딩"을 사용해 각 확률의 분모, 분자에 모두 숫자를 더해 0이 되는 것을 방지
(3) 뉴스그룹 분류
데이터: newsdata.data와 그에 대한 카테고리 레이블인 newsdata.target을 사용
나이브베이즈 분류를 위해 newsdata.data를 BoW로 만든다
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB # 다항분포 나이브 베이즈 모델
from sklearn.metrics import accuracy_score
dtmvector = CountVectorizer()
X_train_dtm = dtmvector.fit_transform(newsdata.data)
print(X_train_dtm.shape) # (11314, 130107) = (DTM 문서의 수, 전체 훈련데이터에 등장한 단어의 수)
DTM 행렬에 TF-IDF 적용
tfidf_transformer = TfidfTransformer()
tfidfv = tfidf_transformer.fit_transform(X_train_dtm)
print(tfidfv.shape) # (11314, 130107)
나이브베이즈 분류 수행
# 사이킷런 나이브 베이즈 모델 사용
mod = MultinomialNB()
mod.fit(tfidfv, newsdata.target)
# 라플라스 스무딩(alpha) 적용
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
# 모델 정확도 평가
newsdata_test = fetch_20newsgroups(subset='test', shuffle=True) # 테스트 데이터 갖고오기
X_test_dtm = dtmvector.transform(newsdata_test.data) # 테스트 데이터를 DTM으로 변환
tfidfv_test = tfidf_transformer.transform(X_test_dtm) # DTM을 TF-IDF 행렬로 변환
predicted = mod.predict(tfidfv_test) # 테스트 데이터에 대한 예측
print("정확도:", accuracy_score(newsdata_test.target, predicted)) # 예측값과 실제값 비교
# 0.7738980350504514
# 10-05 BiLSTM으로 스팀게임 한국어 리뷰 감성분류
(1) BiLSTM 이론 되짚기
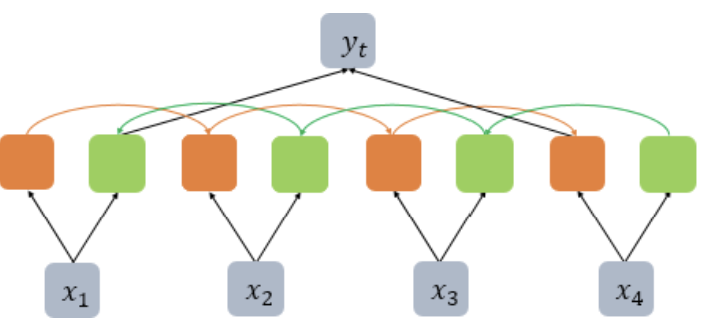
return_sequences=False로 설정하여 위와 같이 순방향 LSTM은 마지막 시점 은닉상태를, 역방향 LSTM은 첫번째 시점 은닉상태를 반환
(2) Colab에 Mecab 설치
# Colab에 Mecab 설치
!git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.git
%cd Mecab-ko-for-Google-Colab
!bash install_mecab-ko_on_colab190912.sh
(3) 다대다 BiLSTM 모델 설계
import re
from tensorflow.keras.layers import Embedding, Dense, LSTM, Bidirectional
from tensorflow.keras.models import Sequential
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
embedding_dim = 100
hidden_units = 128
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(Bidirectional(LSTM(hidden_units))) # Bidirectional LSTM을 사용
model.add(Dense(1, activation='sigmoid'))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train, y_train, epochs=15, callbacks=[es, mc], batch_size=256, validation_split=0.2)
(4) 리뷰 예측
# 입력한 리뷰데이터 자동 전처리 함수
def sentiment_predict(new_sentence):
new_sentence = re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣 ]','', new_sentence)
new_sentence = mecab.morphs(new_sentence) # 토큰화
new_sentence = [word for word in new_sentence if not word in stopwords] # 불용어 제거
encoded = tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩
pad_new = pad_sequences(encoded, maxlen = max_len) # 패딩
score = float(loaded_model.predict(pad_new)) # 예측
if(score > 0.5):
print("{:.2f}% 확률로 긍정 리뷰입니다.".format(score * 100))
else:
print("{:.2f}% 확률로 부정 리뷰입니다.".format((1 - score) * 100))
sentiment_predict('노잼 ..완전 재미 없음 ㅉㅉ')
# 93.66% 확률로 부정 리뷰입니다.스팀 리뷰데이터 다운로드: https://github.com/bab2min/corpus/tree/master/sentiment
'딥러닝 > 딥러닝을 이용한 자연어처리 입문' 카테고리의 다른 글
| [딥러닝 NLP] 12. Tagging Task 실습(NER, POS) (1) | 2024.02.01 |
|---|---|
| [딥러닝 NLP] 11. CNN(Convolution Neural Network) (1) | 2024.01.31 |
| [딥러닝 NLP] 09. 워드 임베딩(Word2Vec, SGNS, GloVe, FastText, ELMo, Doc2Vec) (1) | 2024.01.30 |
| [딥러닝 NLP] 08. 순환신경망(SimpleRNN, LSTM, GRU, CharRNN) (1) | 2024.01.24 |
| [딥러닝 NLP] 07. 딥러닝(2) Keras, NNLM (0) | 2024.01.16 |



