- 이번 장에서는 자연어처리의 정보 검색과 텍스트 마이닝 분야에서 주로 사용되는 카운트 기반 텍스트 표현 방법인
DTM(Document Term Matrix), TF-IDF(Term Frequency-Inverse Document Frequency) 에 대해 살펴본다.
- 어떤 단어가 특정 문서 내에서 갖는 중요도, 문서의 핵심어 추출, 검색 엔진에서 검색 결과의 순위 결정, 문서들 간의 유사도를 구하는 등의 용도로 사용
# 04-01 다양한 단어 표현 방법
1. 국소 표현 (Local Representation)
- 해당 단어 그 자체만 보고, 특정값을 맵핑하여 단어를 표현하는 방법
Ex) puppy(강아지), cute(귀여운), lovely(사랑스러운)라는 단어가 있을 때 각 단어에 1번, 2번, 3번 맵핑(mapping)
- 이산 표현(Discrete Representation) 이라고도 부름
2. 분산 표현(Distributed Representation)
- 그 단어를 표현하고자 주변을 참고하여 단어를 표현하는 방법
Ex) puppy라는 단어는 cute, lovely한 느낌이다로 단어를 정의 -> 단어의 뉘앙스 표현 가능!
- 연속 표현(Continuous Represnetation)이라고도 부름
3. 단어 표현의 카테고리화

# 04-02 BoW : Bag of Words
1. BoW란?
-빈도수 기반 단어 표현, 순서는 고려 X
-단순 빈도수 기반이기 때문에 불용어 제거 필수
-1단계: 단어에 인덱스 부여, 2단계: 각 인덱스 위치에 등장 횟수 기록
Ex) vocabulary : {'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9} 일 때,
bag of words vector : [1, 2, 1, 1, 2, 1, 1, 1, 1, 1]
-용도: 자주 등장하는 단어 바탕으로 어떤 성격의 문서인지 판단하는 작업에 사용
2. CountVectorizer로 BoW 사용
from sklearn.feature_extraction.text import CountVectorizer 로 간단히 실습 가능
-띄어쓰기 기준으로 자르기 때문에 한국어 적용 어려움
ex) '물가상승률', '물가상승률은' -> 서로 다른 두 단어로 인식
3. 불용어 제거 방법
-CountVectorizer에서 제공하는 자체 불용어
from sklearn.feature_extraction.text import CountVectorizer
-NLTK에서 제공하는 불용어 사용
from nltk.corpus import stopwords
-사용자 정의 불용어 사용
# 04-03 문서 단어 행렬(DTM, Document-Term Matrix)
1. DTM 이란?
-DTM: 다수의 문서에서 등장하는 BoW들을 하나의 행렬로 표현( 장점: 문서간 비교 가능)
-TDM: 행과 열을 반대로 선택
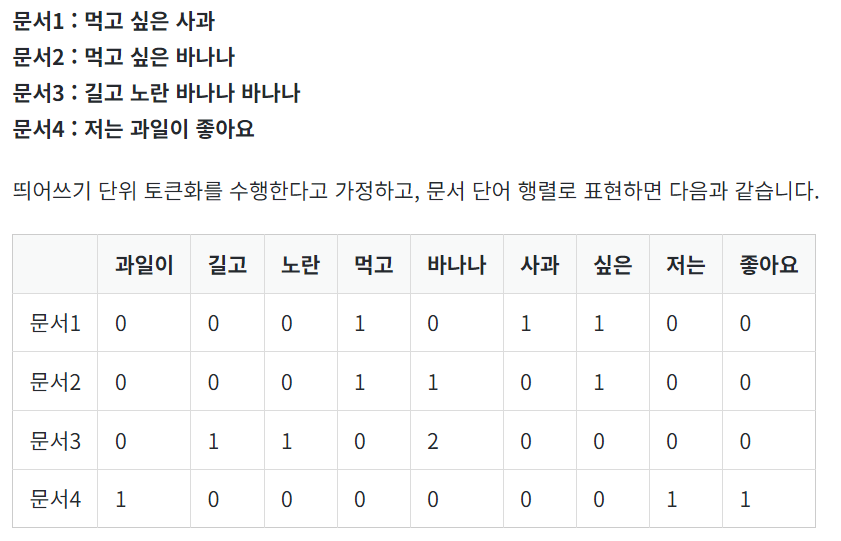
2. DTM의 한계
-희소표현: 원핫벡터와 같이 대부분의 값이 0인 희소표현 사용하므로 저장공간 낭비
-단순 빈도수 접근이므로 문서간 유사도 판단 한계
ex) 문서1, 문서2, 문서3 모두 the 라는 단어 빈도수 높다고 유사한 문서는 아님
# 04-04 TF-IDF(Term Frequency-Inverse Document Frequency)
1. TF-IDF 란?
-단어의 빈도(TF)와 역문서빈도(IDF)를 곱하여 각 단어의 중요한 정도에 따라 가중치를 주는 방법
-용도: 문서 유사도 구하기, 검색 시스템에서 검색결과의 중요도 정하기, 문서 내 특정 단어의 중요도 구하기
2. 문서=d, 단어=t, 문서개수=n 일 때
-1단계 df(t) : 특정단어 t 포함 문서개수
-2단계 idf(t) : 총문서개수 n / 특정단어 t 포함 문서개수

-식에 log를 사용하는 이유: 불용어 >>>>> 자주 쓰이는 단어 >> 희귀 단어 이기 때문에 엄청난 가중치 격차 줄이기 위해서
-분모에 1을 더하는 이유: 특정 단어가 전체 문서에서 등장하지 않아 분모가 0이 되는 상황 방지
-3단계 tf(d,t) : 어떤문서 d 에서 특정단어 t 의 빈도
-4단계: 2단계와 3단계를 곱해줌
-TF-IDF 값이 높다 = 모든 문서에서 자주 등장하는 단어여서 중요도 낮다 (ex. the)
-TF-IDF 값이 낮다 = 특정 문서에만 자주 등장하는 단어여서 중요도 높다
- t 라는 단어가 내가 보고자 하는 문서 내에서 많이 등장할수록 중요하고, 전체 문서에 걸쳐 많이 등장할수록 안 중요하다
3. TF-IDF 파이썬 구현
-사이킷런이 제공하는 TF-IDF는 기본 식에서 약간 값 조정됨. (1) IDF 분자 +1 (2) 로그항 +1 (3) TF-IDF에 L2 정규화
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfv = TfidfVectorizer().fit(corpus)
tfidfv.transform(corpus).toarray()
tfidfv.vocabulary_
'딥러닝 > 딥러닝을 이용한 자연어처리 입문' 카테고리의 다른 글
| [딥러닝 NLP] 06. 머신러닝(Linear, Logistic, Softmax Regression) (2) | 2023.12.06 |
|---|---|
| [딥러닝 NLP] 05. 벡터의 유사도(코사인, 유클리드, 자카드) (0) | 2023.11.29 |
| [딥러닝 NLP] 03. 언어 모델 (0) | 2023.10.18 |
| [딥러닝 NLP] 02. 텍스트 전처리 (2) | 2023.10.16 |
| [딥러닝 NLP] 01. 자연어처리 준비하기 (0) | 2023.03.05 |


