문서의 유사도 : 문서들 간에 동일하거나 비슷한 단어가 공통적으로 사용된 정도
성능: 단어 표현 방법(DTM, Word2Vec 등) 과 유사도 기법(유클리드 거리, 코사인 유사도 등) 에 따라 달라짐
# 05-01 코사인 유사도(Cosine Similarity)
1. 코사인 유사도란?
-두 벡터가 가리키는 방향이 유사한 정도를 코사인 각도로 구하는 기법
-동일 = 1, 90° = 0, 180° = -1 이므로, -1 이상 1 이하이며 1에 가까울수록 유사
-특징: 문서의 길이가 다른 상황에서 비교적 공정한 비교 가능
Ex) 문서A, 문서B는 내용 비슷한데 길이는 2배 차이 / 문서A, 문서C는 다른 내용인데 길이는 비슷한 경우
유클리드 거리는 길이의 영향 받아 A와 C의 유사도가 더 높게 나와버리지만,
코사인 유사도는 내용(벡터방향)에 영향 받으므로 A와 B의 유사도가 더 높게 나옴
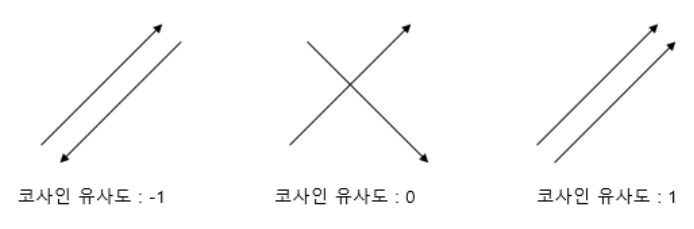

2. 코사인 유사도 구하기
-1단계: 문서를 벡터화 (DTM, TF-IDF 등)
-2단계: 넘파이로 코사인 유사도 함수 구현해 계산
3. TF-IDF와 코사인유사도로 영화추천시스템 구현
-캐글 영화 데이터셋 링크: https://www.kaggle.com/rounakbanik/the-movies-dataset
-1단계: TF-IDF 연산시 결측값 존재하면 에러 발생하므로 결측값 처리
-2단계: overview 컬럼에 대한 TF-IDF 구하기
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(data['overview'])
-3단계: 코사인 유사도 구하기
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
-4단계: title을 key, 인덱스를 value로 하는 딕셔너리 생성후 overview의 코사인 유사도가 높은 순서대로 정렬하는 함수 생성
# 05-02 여러가지 유사도 기법
1. 유클리드 거리(Euclidean distance)

-2차원에서의 피타고라스 정리를 다차원(총 단어개수)으로 확장하여 계산. 값 작을수록 가깝다(=문서가 유사하다)
Ex. 문서 1,2,3의 DTM을 구했더니 단어 4개 -> 비교기준인 문서Q도 4차원 공간에 배치해 각 문서에 대한 거리 구함
2. 자카드 유사도(Jaccard similarity)
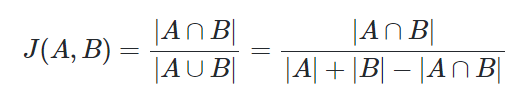
-합집합 중의 교집합의 비율. 0~1 사이 값 가짐(동일하면 1, 공통원소 없다면 0)
Ex)
문서1 : ['apple', 'banana', 'everyone', 'like', 'likey', 'watch', 'card', 'holder']
문서2 : ['apple', 'banana', 'coupon', 'passport', 'love', 'you']
합집합 단어 개수: 12, 교집합 단어 개수: 2, 자카드 유사도= 2/12 = 0.16666666666
'딥러닝 > 딥러닝을 이용한 자연어처리 입문' 카테고리의 다른 글
| [딥러닝 NLP] 07. 딥러닝(1) 활성화함수,손실함수,옵티마이저,역전파, 과적합, 기울기소실, 기울기폭주 (2) | 2024.01.11 |
|---|---|
| [딥러닝 NLP] 06. 머신러닝(Linear, Logistic, Softmax Regression) (2) | 2023.12.06 |
| [딥러닝 NLP] 04. 카운트 기반 단어 표현(BoW, DTM, TF-IDF) (1) | 2023.11.27 |
| [딥러닝 NLP] 03. 언어 모델 (0) | 2023.10.18 |
| [딥러닝 NLP] 02. 텍스트 전처리 (2) | 2023.10.16 |



