# 07-01 딥러닝의 개념
딥러닝은 머신러닝의 한 분야로, 인공신경망의 층을 연속적으로 깊게 쌓아올려 학습하는 방식을 말한다.
이해를 쉽게 하기 위해 퍼셉트론, 인공신경망 ,딥러닝의 순서로 학습한다.
1. 퍼셉트론(Perceptron)
(1) 퍼셉트론의 개념
-신경 세포 뉴런과 유사한 알고리즘
-입력값 x와 가중치 w를 곱해서 모두 더한것이 임계치를 넘으면 1, 넘지 않으면 0을 출력값 y로 출력
-이 때, 임계치를 좌변으로 넘겨서 입력값 1과 편향 b가 곱해지는 그림으로 자주 표현

-활성화함수: 뉴런에서 출력값을 변경시키는 함수
-인공뉴런의 활성화함수: 시그모이드, 소프트맥스 함수, 계단함수 등
-퍼셉트론(인공뉴런의 한 종류)의 활성화함수: 계단함수 (0 아니면 1 출력)
(2) 단층 퍼셉트론과 다층 퍼셉트론
-단층 퍼셉트론: 입력층과 출력층, 총 두 개의 층으로만 이루어진 퍼셉트론
-AND, NAND, OR 게이트는 구현가능, XOR 게이트는 구현 불가능 -> 다층 퍼셉트론 등장
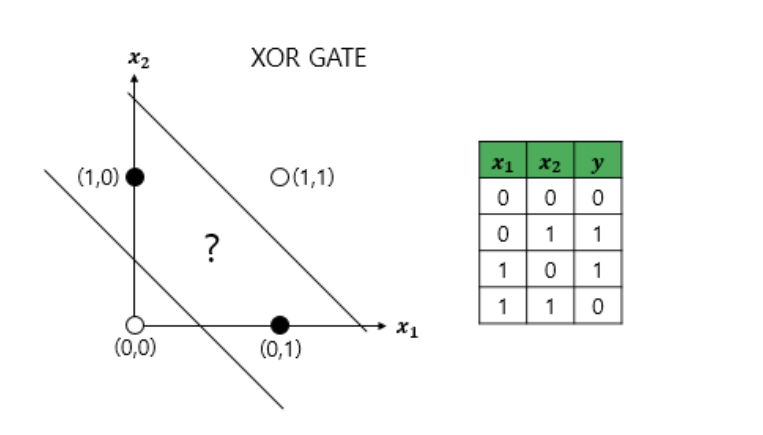
-다층 퍼셉트론: 입력층과 출력층 사이에 n개의 은닉층이 존재, XOR 게이트 구현 가능
-은닉층이 2개 이상이면 심층 신경망(Deep Neural Network, DNN)
-손실함수, 옵티마이저를 사용해 가중치를 자동으로 찾도록 학습, DNN을 학습시키는 것이 딥러닝
2. 인공신경망(Artificial Nerual Network)
(1) 피드 포워드 신경망(FFNN)
-순방향 신경망(Feed-Forward Neural Network): 입력층에서 출력층으로 순방향 연산 전개
-순환 신경망(Recurrent Neural Network): 은닉층의 출력값이 출력층으로뿐 아니라 다시 은닉층의 입력으로도 사용
(2) 전결합층(Fully-connected layer, FC)
-이전층과 다음층의 모든 뉴런이 서로 연결되어 있는 층
-완전연결층, 밀집층(Dense layer) 라고도 부름
3. 행렬곱으로 신경망 이해하기
(1) 순전파(Forward Propagation)란?
입력층에서 출력층 방향으로 연산을 전개하는 과정

(2) 행렬곱으로 순전파 이해하기

위 인공신경망의 활성화함수로 소프트맥스를 사용한다고 가정하자.

-행렬곱 관점에서는 3차원 벡터에서 2차원 벡터가 되기 위해 3x2 행렬을 곱하고, 출력층에 맞춰 편향 더해준 것
-즉, 가중치 3x2=6개, 편향 2개로 학습가능한 매개변수는 총 8개(케라스의 model.summary()로 확인 가능)
(3) 행렬곱으로 병렬연산(배치연산) 이해하기

-배치연산: 인공신경망이 다수의 샘플을 동시에 처리하는 것
-위와 같이 4개의 샘플을 동시에 처리해도 학습가능한 매개변수의 수는 여전히 8개
(4) 행렬곱으로 다층퍼셉트론의 순전파 이해하기

위 인공신경망의 구현 코드
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
# a개의 입력과 b개의 출력 설정하여 딥러닝 모델의 층 구현
model.add(Dense(b, input_dim=a, activation='relu'))
1) 입력층(1x4) -> 은닉층1(1x8) : W는 4x8, B는 1x8
2) 은닉층1(1x8) -> 은닉층2(1x8) : W는 8x8, B는 1x8
3) 은닉층2(1x8) -> 출력층(1x3): W는 8x3, B는 1x3
* 이처럼 순전파 과정을 거쳐 예측값을 구했다면,
그다음은 예측값과 실제값의 오차를 계산하고 가중치와 편향을 업뎃하는 것(=역전파, BackPropagation)
# 07-02 딥러닝(Deep Learning)
1. 딥러닝의 학습과정
입력층, 은닉층, 출력층 등으로 이루어진 신경망의 형태에서,
1. 각 층의 노드는 가중치와 활성화함수를 거쳐 다음 층으로 향함(순전파)
2. 출력층까지 도달했다면 손실함수를 정의하고 손실을 계산
3. 이 손실을 최소화하기 위한 옵티마이저(주로 경사하강법)을 선택하고 역전파를 수행하며 가중치 업데이트
4. 이 과정을 여러 번의 학습 주기(epoch)에 거쳐 반복하며 모델을 데이터에 더 적응시킴
5. 학습이 완료된 모델을 평가 데이터에 적용하여 성능을 평가
이제부터 활성화함수, 손실함수, 옵티마이저(특히 경사하강법), epoch/batch/iteration, 역전파에 대하여 공부한다.
2. 활성화함수
(1) 활성화함수 특징
-비선형함수임. 은닉층을 쌓으려면 비선형이어야 함
-선형층(linear layer), 투사층(projection layer): 선형함수를 사용한 층. 활성화함수가 존재하지 않음
-비선형층(nonlinear layer): 일반적인 은닉층
-종류: 계단함수, 시그모이드함수, 하이퍼볼릭탄젠트함수, 렐루함수, 리키렐루, 소프트맥스함수 등
(2) 시그모이드 함수
-0과 1 사이의 출력값

위 인공신경망의 학습과정은 다음과 같다.
순전파연산 -> 손실함수로 오차계산 -> 손실 미분해 기울기구함 ->경사하강법으로 역전파(가중치,편향 업데이트)

- 기울시 소실(Vanishing Gradient): 시그모이드 함수의 미분값이 너무 작아 역전파 과정에서 가중치 업뎃 잘 안되는 문제
-> 은닉층이 깊어질수록 심해지므로, 시그모이드는 주로 이진 분류시 출력층에 사용
(3) 하이퍼볼릭탄젠트 함수(tanh)
-1과 1 사이의 출력값

-여전히 기울기소실 문제가 있으나 시그모이드 함수보다는 덜해서 은닉층으로 보다 선호되는 편
(4) 렐루 함수(ReLU)
-은닉층에서 가장 인기있는 함수
-음수를 입력하면 0을, 양수를 입력하면 그대로를 출력

-장점: 양수에 대한 미분값이 항상 1, 연산이 필요하지 않아 빠름, 깊은 은닉층에서 매우 잘 작동
-단점: 음수에 대한 미분값이 0 이 되어 회생이 어려움. "죽은렐루(dying ReLU)"
(5) 리키 렐루(Leaky ReLU)
-죽은 렐루에 대한 보완책으로 등장 (은닉층)
-식은 f(x)=max(ax,x)로, 음수를 입력하면 0이 아닌 매우 작은 수를 반환

(6) 소프트맥스 함수(softmax function)
-시그모이드가 이진분류 출력층에 주로 쓰였다면 소프트맥스는 다중클래스분류 출력층에 주로 사용

* 즉, 딥러닝으로 이진분류 할때는 출력층에 logistic regression을, 다중클래스분류 할때는 출력층에 softmax regression
3. 손실함수
(1) 손실함수(Loss function) 개념
-실제값과 예측값의 오차를 구하는 함수
-손실함수 값을 최소화하는 w와 b를 찾는 것이 딥러닝의 학습 과정
(2) 평균제곱오차(Mean Squared Error, MSE)
-연속형 변수 예측에 사용
model.compile(optimizer='adam', loss='mse', metrics=['mse'])
(3) 이진 크로스 엔트로피(Binary Cross-Entropy)
-이진 분류에 사용
-이항 교차 엔트로피라고도 부름
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
(4) 카테고리칼 크로스 엔트로피(Categorical Cross-Entropy)
-다중 클래스 분류에 사용
-범주형 교차 엔트로피라고도 부름
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])-만약 원핫인코딩 과정 생략하고 정수값 레이블 그대로 쓰고싶다면
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
(5) 그 외 다양한 손실함수들 : https://www.tensorflow.org/api_docs/python/tf/keras/losses
Module: tf.keras.losses | TensorFlow v2.14.0
signature_constants
www.tensorflow.org
4. 옵티마이저
4.1. 배치크기에 따른 경사하강법
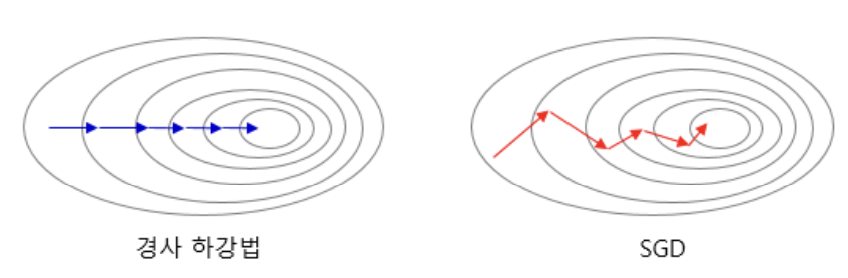
(1) 배치 경사하강법(Batch Gradient Descent)
-한 번의 epoch에 모든 매개변수 업데이트를 단 한 번 수행(배치크기: 전체데이터)
-epoch: 전체 데이터에 대한 훈련 횟수
-시간이 오래 걸리고 메모리 크게 요구
model.fit(X_train, y_train, batch_size=len(X_train))
(2) 확률적 경사하강법(Stochastic Gradient Descent, SGD)
-전체 데이터가 아닌 랜덤으로 선택한 하나의 데이터에 대해 매개변수값 조정 (배치크기: 1)
model.fit(X_train, y_train, batch_size=1)
(3) 미니 배치 경사하강법(Mini-Batch Gradient Descent)
-지정한 배치크기에 대해 매개변수값 조정 (배치크기: 사용자지정)
-배치 경사하강법보다 빠르고, 확률적 경사하강법보다 안정적
model.fit(X_train, y_train, batch_size=128)
4.2. 그 외 옵티마이저
(1) 모멘텀(Momentum)
-경사하강법으로 계산된 기울기에 한시점 전의 기울기값을 일정비율만큼 반영해 관성을 더해줌
-장점: 로컬미니멈에 도달시 관성의 힘을 빌려 더 낮은 로컬미니멈 혹은 글로벌미니멈으로 갈 수도 있음

tf.keras.optimizers.SGD(lr=0.01, momentum=0.9)
(2) 아다그라드(Adagrad)
-변화가 많은 매개변수에는 작은 학습률, 변화가 적은 매개변수에는 높은 학습률 설정
-단점: 학습을 계속 진행하다보면 학습률이 지나치게 떨어짐
tf.keras.optimizers.Adagrad(lr=0.01, epsilon=1e-6)
(3) 알엠에스프롭(RMSprop)
아다그라드를 다른 수식으로 대체하여 단점을 극복
tf.keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-06)
(4) 아담(Adam)
Momentum(방향) + RMSprop(학습률)
tf.keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
(5) 옵티마이저 사용법
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
5. Epoch, Batch, Iteration

-에포크: 전체 데이터에 대해 순전파와 역전파가 끝난 상태(ex. epoch=50이면 전체 데이터에 대해 50회 학습)
-배치크기: 몇 개의 단위로 매개변수를 업데이트하는지
-이터레이션=스텝=배치수: 한 번의 에포크 안에서 업데이트가 이루어지는 횟수
ex.전체 데이터=2000개, 배치크기=200, 이터레이션=10. 즉, 한 이터레이션마다 200개의 데이터 선택해 경사하강법 수행
6. 역전파(Back Propagation)
다음과 같은 인공신경망이 있다고 가정하자.

(1) 먼저 순전파 연산을 진행한다.
입력층 노드 x 에 가중치 w 를 곱해서 z 가 된다. 은닉층 노드 z 에 활성화함수(ex.시그모이드)를 적용해 h 가 된다.
은닉층 노드 h 에 가중치 w 를 곱해서 z 가 된다. 출력층 노드 z 에 활성화함수(ex.시그모이드)를 적용해 o 가 된다.
(2) 손실함수를 정의하고 오차를 계산한다.
손실함수(ex.MSE)를 정의한다.
출력값 o 와 실제값 사이의 오차를 계산한다.
(3) 역전파 1단계를 수행한다.

역전파 1단계에서는 w5,w6,w7,w8을 갱신한다.
옵티마이저를 경사하강법으로 정의하고 학습률a를 0.5로 정의했을 때, 먼저 w5를 갱신하는 과정을 살펴보자.


는 미분의 연쇄법칙(Chain rule)에 따라 다음과 같이 풀어쓸 수 있다.
( 미분의 연쇄법칙: 합성함수의 미분은 각 함수의 미분을 곱한 것과 같다 )

우변의 각 항을 계산하면 다음과 같다.

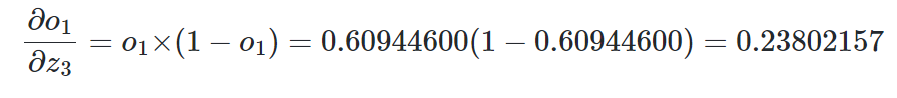

이제 우변의 세 항을 모두 곱해준다.

따라서 처음 구하고자 했던 갱신된 w5의 값은 다음과 같다.

이제 w5를 갱신한 것처럼 w6,w7,w8도 갱신한다.

(4) 역전파 2단계를 수행한다.

역전파 2단계에서는 w1,w2,w3,w4를 갱신한다.
옵티마이저를 경사하강법으로 정의하고 학습률a를 0.5로 정의했을 때, 먼저 w1을 갱신하는 과정을 살펴보자.


는 미분의 연쇄법칙에 의해 다음과 같이 풀어서 쓸 수 있다.

우변의 각 항을 계산하면 다음과 같다.
첫번째 항


+


두번째 항

세번째 항

이제 우변의 세 항을 모두 곱해준다.

따라서 처음 구하고자 했던 갱신된 w1의 값은 다음과 같다.

이제 w1을 갱신한 것처럼 w2,w3,w4도 갱신한다.

(5) 업데이트된 가중치로 순전파를 진행해 오차가 감소하였는지 확인한다.
(6) 1~5의 과정을 반복하며 오차를 최소화하는 가중치를 찾는다.
# 07-03 과적합(Overfitting)을 막는 방법
1. 데이터 양 늘리기
-데이터 증식/증강(Data Augmentation): 데이터의 양이 적을 때, 기존 데이터를 변형하거나 추가하여 양을 늘리는 방법
-이미지데이터: 데이터 증식(이미지 회전, 노이즈 추가, 일부분 수정 등)
-텍스트데이터: 데이터 증강(번역 후 재번역하는 역번역(Back Translation))
2. 모델 복잡도 줄이기
은닉층, 매개변수의 개수(=모델의 수용력, capacity) 등을 줄이는 것
3. 가중치 규제(Regularization)
-정규화(Normalization)와는 다른 개념
-L1규제, L2규제가 있으며 둘 다 하이퍼파라미터 람다를 크게 할수록 규제의 강도가 심해짐
(1) L1 규제

들의 합을 비용함수에 추가
-모델의 결과에 영향을 별로 주지 못하는 특성들은 가중치 w 가 0이 되거나 0에 가까워짐
-어떤 특성들이 모델에 영향을 주는지 정확히 판단하고자 할 때 유용
(2) L2 규제(=가중치 감쇠, weight decay)

들의 합을 비용함수에 추가
-L1규제와의 차이: 절대값이 아닌 제곱을 사용하므로 w 가 완전히 0이 되기보다는 0에 가까워지는 경향 보임
-L1규제보다 더 잘 작동하므로 L1규제를 써야할 필요가 없다면 L2규제를 권장
4. 드롭아웃(Dropout)
신경망의 일부를 사용하지 않는 것

-매번 랜덤으로 학습자가 설정한 드롭아웃의 비율만큼의 뉴런을 사용
-학습시 신경망이 특정 뉴런이나 조합에 의존하는 것을 방지하는 목적이므로, 예측시에는 사용 안 함
-드롭아웃 추가 코드
from tensorflow.keras.layers import Dropout
model.add(Dropout(0.5)) # 드롭아웃 추가. 비율은 50%
# 07-04 기울기소실과 기울기폭주를 막는 방법
1. 기울기소실, 기울기폭주란?
-기울기소실(Gradient Vanishing): 역전파에서 입력층으로 갈수록 기울기가 작아져 가중치 업뎃이 제대로 되지 않는 문제
-기울기폭주(Gradient Exploding): 역전파에서 입력층으로 갈수록 기울기가 커져 가중치가 비정상적으로 커져 발산해버리는 문제. 특히 순환신경망(RNN)에서는 시점을 역행하면서 기울기를 구하기 때문에 자주 발생
2. ReLU, Leaky ReLU
기울기소실에 대한 해결방법으로, 은닉층의 활성화함수로 ReLU 혹은 Leaky ReLU 사용
3. Gradient Clipping
기울기폭주에 대한 해결방법으로, 임계값을 넘지 않도록 기울기 값을 잘라 감소시키는 것
from tensorflow.keras import optimizers
Adam = optimizers.Adam(lr=0.0001, clipnorm=1.)
4. 가중치 초기화
-기울기들의 분산의 균형을 맞추어 특정 층이 튀는 것을 방지하는 것
-ReLU + He 초기화 방법이 보편적
(1) 셰이비어 초기화(Xavier Initialization)
이전층과 다음층 뉴런 사용. 시그모이드, 하이퍼볼릭탄젠트 등 S자 함수에 유용
(2) He 초기화(He initialization)
이전층 뉴런만 사용. ReLU 계열 함수에 유용
5. 배치 정규화
각 층에서 활성화함수를 통과하기 전에 배치단위로 정규화하는 것
(1) 내부 공변량 변화(Internal Covariate Shift)
-공변량 변화: 훈련데이터의 분포와 테스트데이터의 분포가 다른 것
-내부 공변량 변화: 신경망 층 사이에서 입력 데이터의 분포가 변화하는 것
-이전층의 가중치 값이 바뀌면, 현재층에 전달되는 입력데이터의 분포가 현재층이 학습했던 시점의 분포와 달라짐
-> 이에 대한 반박 논문 나옴( https://arxiv.org/pdf/1805.11604.pdf )
(2) 배치 정규화(Batch Normalization)
-학습시 배치단위의 평균과 분산들을 차례대로 받아 이동평균과 이동분산을 저장해두었다가, 테스트시 해당 배치의 평균과 분산을 구하지 않고 저장해두었던 평균과 분산으로 정규화하는 것
-장점: S자 활성화함수와 함께 써도 기울기소실문제 개선/가중치 초기화에 덜 민감해짐/큰 학습률을 사용할 수 있어 학습속도 개선/드롭아웃과 비슷한 효과, 그래도 둘 다 쓰는 것이 좋음
-단점: 모델이 복잡해져서 테스트데이터에 대해 실행시간 느려짐
(3) 배치 정규화 한계
-미니배치가 너무 작으면 배치정규화가 극단적으로 작용해 훈련에 악영향
* 미니배치: 동일한 특성개수를 가진 다수의 샘플
-RNN은 각 시점마다 다른 통계치를 가지므로 적용이 어려움 -> 대안: 층 정규화(layer normalization)


'딥러닝 > 딥러닝을 이용한 자연어처리 입문' 카테고리의 다른 글
| [딥러닝 NLP] 08. 순환신경망(SimpleRNN, LSTM, GRU, CharRNN) (1) | 2024.01.24 |
|---|---|
| [딥러닝 NLP] 07. 딥러닝(2) Keras, NNLM (0) | 2024.01.16 |
| [딥러닝 NLP] 06. 머신러닝(Linear, Logistic, Softmax Regression) (2) | 2023.12.06 |
| [딥러닝 NLP] 05. 벡터의 유사도(코사인, 유클리드, 자카드) (0) | 2023.11.29 |
| [딥러닝 NLP] 04. 카운트 기반 단어 표현(BoW, DTM, TF-IDF) (1) | 2023.11.27 |



