이번 장에서는 머신러닝의 개념, linear regression, logistic regression, softmax regression 대해 알아본다.
# 06-01 머신러닝이란?
-데이터가 주어지면 기계가 스스로 규칙성을 찾아내는 훈련(training) 또는 학습(learning)의 과정
-사람이 직접 규칙을 정의하는 것보다 모델이 스스로 규칙을 찾아내도록 구현하는것이 훨씬 성능 좋음
# 06-02 머신러닝 개요
1. 머신러닝 모델 평가

-훈련 데이터로 모델을 학습(이 때 가중치, 편향 등은 학습과정에서 자동으로 얻어짐)
-검증용 데이터에 대해 높은 정확도를 얻도록 하이퍼파라미터를 튜닝(사용자가 수정)
-튜닝을 마친 최종모델을 테스트 데이터에 적용
2. 분류와 회귀
-분류: 이진분류, 다중 클래스 분류
-회귀: 분류와 달리 연속적 값을 결과로 가짐 (ex.시계열 데이터로 주가 예측)
3. 지도학습과 비지도학습
-지도학습: 데이터와 레이블(정답)을 함께 학습하는 것
-비지도학습: 레이블 없이 데이터만 학습하는 것
ex.토픽모델링
-자기지도학습(Self-Supervised Learning): 레이블 없는 데이터에 대해 모델이 스스로 레이블을 만들어 학습
ex.Word2Vec, BERT
4. 샘플과 특성
-샘플:하나의 행
-특성:하나의 열(독립변수)
5. Confusion Matrix(혼동행렬)


1) 정밀도(Precision): 다 True라고 하긴 했는데 얼마나 정밀한 True인지, 모델이 예상한 True 값 중 실제 True 값
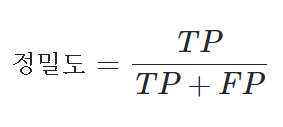
2) 재현율(Recall): 실제 True 값 중에 모델이 얼마나 True로 잘 재현했는지

3) 정확도(Accuracy): 모델의 전체 예측값 중에서 맞춘 정답의 비율

-한계: 실질적으로 중요한 데이터가 전체 데이터 중에서 너무 적은 비율을 차지할 때 정확도는 좋은 측정지표X
-대책: F1-Score 사용
6. 과적합과 과소적합
-과적합(Overfitting): 훈련데이터는 정확도 너무 높고 테스트데이터는 정확도 낮음
-대책: Dropout, Early Stopping 등
-과소적합(Underfitting): 훈련데이터, 테스트데이터 모두 정확도 낮음
* 검증데이터와 과적합
훈련데이터로 모델 학습 후, 검증데이터에 대한 오차를 구한다.
검증데이터에 대한 오차가 감소했다면 다시 학습하고 다시 검증한다.
검증데이터에 대한 오차가 증가했다면 과적합 징후이므로 학습을 종료한다.
테스트 데이터로 최종평가한다.
# 06-03 Linear Regression
1. Linear regression 이란?
-독립변수 x와 종속변수 y의 선형 관계를 모델링하는것. 가설 H(x)=wx+b일 때, x와 y의 관계를 유추한 수학적 식
-simple linear regression: y=wx+b
-multiple linear regression: y= w1x1 + .... + wnxn + b
2. Linear Regression의 비용함수: 평균제곱오차(MSE)
-목적함수: 실제값과 예측값의 오차값 식. 이 오차값을 최소화or최대화하는 목적을 가져서 목점함수라고 함
-목적함수 중 최소화가 목적인 경우 비용함수, 손실함수라고도 함
-Linear Regression에 적합한 비용함수: 평균제곱오차(MSE), 모든 오차를 제곱해 더하여 평균을 구함
3. Linear Regression의 옵티마이저: 경사하강법(Gradient Descent)
-옵티마이저: 비용함수를 최소화하는 최적화 알고리즘
-머신러닝에서의 옵티마이저는 훈련(training) 혹은 학습(learning)
-경사하강법: 비용함수를 미분해 접선의 기울기를 구하고, 그 기울기가 0으로 향햐도록 w 값을 반복해서 변경
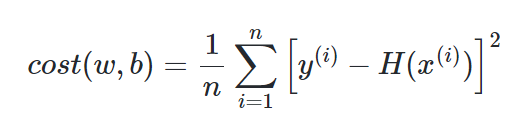
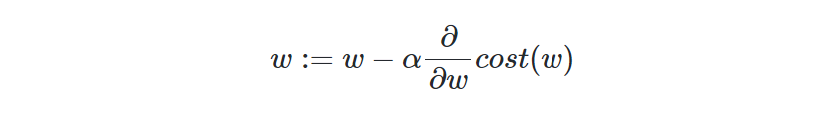
- (현재w) - {(현재 w에서의 기울기) x (학습률 a)}
-학습률 a가 너무 크면 cost가 발산, 너무 작으면 학습속도가 느림
# 06-04 Simple Linear Regression 실습
실습코드 -> https://wikidocs.net/111472
06-04 자동 미분과 선형 회귀 실습
선형 회귀를 텐서플로우와 케라스를 통해 구현해봅시다. ## 1. 자동 미분 ```python import tensorflow as tf ``` tape_gradient()는…
wikidocs.net
# 06-05 Logistic Regression
1. Logistic Regression의 활용: 이진분류
-직선은 음의무한대, 양의무한대에 대한 분류문제에 적합X
-출력이 0과 1 사이의 값을 가지면서 S자 곡선인 시그모이드 함수 사용
2. Logistic Regression의 개념 : 시그모이드 함수

-w와 b값에 따라 경사가 달라짐
-입력값이 클수록 1에, 작을수록 0에 수렴
-출력값을 0.5 기준으로 1 아니면 0으로 나눔으로써 이진분류에 사용 가능
3. Logistic Regression의 비용함수: Cross Entropy 함수
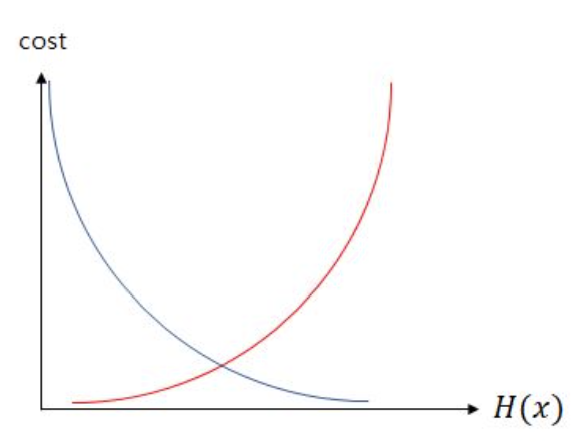
-logistic regression에서 MSE를 쓰면 local minimum에 빠질 가능성 높음
-local minimum이란? 아래 그림 참고

-따라서, logistic regression에서는 목적함수로 Cross Entropy 함수 사용

4. Logistic Regression의 옵티마이저: 경사하강법
# 06-06 Simple Logistic Regression 실습
실습코드 -> https://wikidocs.net/111476
# 06-07 Multiple Linear / Logistic Regression 실습
실습코드 -> https://wikidocs.net/35821
# 06-08 벡터와 행렬연산
1. 벡터, 행렬, 텐서
-벡터: 1차원 배열
-행렬: 2차원 배열
-텐서: 3차원 이상의 배열
2. 텐서
-numpy의 ndim을 출력해서 나오는 값을 축(axis)의 개수 혹은 텐서의 차원이라고 부름
1) 0차원 텐서: 스칼라
2) 1차원 텐서: 벡터(벡터의 차원: 하나의 축에 놓인 원소의 개수, 텐서의 차원: 축의 개수)
ex) [1,2,3,4] 는 1차원 텐서이자 4차원 벡터
3) 2차원 텐서: 행렬 (2차원 배열)
4) 3차원 텐서: 다차원배열 (3차원 이상 배열), 특히 자연어처리에서 시퀀스 데이터를 표현할 때 자주 사용
5) 케라스에서 입력 줄 때 input_shape 인자 사용하는데, (batch_size, timesteps, word_dim) 중 배치크기 제외하고 지정
ex) input_shape(6,5) 는 (?,6,5)를 의미
-> batch_input_shape(6,2,5) 사용시 배치크기까지 지정 가능
3. 벡터와 행렬 기본연산
-요소별 연산(element-wise): 같은 크기의 벡터나 행렬은 같은 위치 원소끼리 연산
-벡터의 점곰(dot product) 또는 내적(inner product): 행벡터 곱하기 열벡터 = 스칼라
* 내적의 정의: 대응하는 원소들의 곱의 합
4. Multiple linear regression 을 행렬연산으로 이해하기
-수학적 관례로 가중치 W를 입력X 앞에 적어주는 편
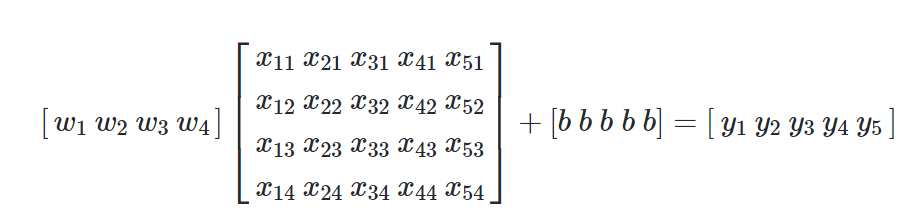
5. W 와 B 의 shape 결정하기
-입력 X와 출력 Y의 shape을 알 때, 중간에 낀 W와 B의 shape을 알 수 있음
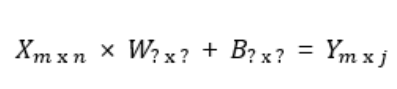


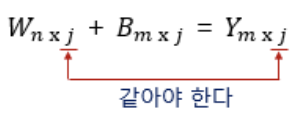
# 06-09 Softmax Regression
1. Softmax Regression의 활용: 다중클래스 분류
-logistic regression이 이진분류에 사용됐다면, softmax regression은 다중클래스 분류에 사용
-출력레이블 각각에 대응할 확률을 총합이 1이 되도록 계산해, 가장 높은 확률의 레이블로 예측하는 방식
2. Softmax function의 개념
-입력 shape와 출력 shape에 맞추어 W와 B의 shape이 정해진다

-오차계산방법: "예측결과"와 "실제값을 원핫벡터로 표현한것"을 비교, 비용함수는 Cross Entropy 함수 사용

3. Softmax에서 원핫벡터를 사용하는 이유
-다중 클래스 분류 문제에서 정수 인코딩(1,2,3,4)이 아니라 원핫인코딩(0,1,0,0)이 나은 이유?
: 각 클래스는 순서의 의미를 갖지 않으므로 각 클래스 간 오차를 균등하게 해주려면 0, 1 만 사영하는 것이 보다 타당
: 즉, 각 클래스의 표현 방법이 무작위성을 가짐 (단점: 단어간 유사성 구할 수 없음)
4. Softmax Regression의 비용함수: Cross Entropy
소프트맥스 함수의 최종 비용 함수에서 k가 2라고 가정하면 결국 로지스틱 회귀의 비용 함수와 같음


# 06-10 Softmax Regression 실습
실습 코드 링크 -> https://wikidocs.net/157265
'딥러닝 > 딥러닝을 이용한 자연어처리 입문' 카테고리의 다른 글
| [딥러닝 NLP] 07. 딥러닝(2) Keras, NNLM (0) | 2024.01.16 |
|---|---|
| [딥러닝 NLP] 07. 딥러닝(1) 활성화함수,손실함수,옵티마이저,역전파, 과적합, 기울기소실, 기울기폭주 (2) | 2024.01.11 |
| [딥러닝 NLP] 05. 벡터의 유사도(코사인, 유클리드, 자카드) (0) | 2023.11.29 |
| [딥러닝 NLP] 04. 카운트 기반 단어 표현(BoW, DTM, TF-IDF) (1) | 2023.11.27 |
| [딥러닝 NLP] 03. 언어 모델 (0) | 2023.10.18 |



