다양한 자연어처리 태스크가 트랜스포머로 대체되어가는 추세에 따라 트랜스포머 계열의 BERT, GPT, T5 등의 사전 훈련된 언어 모델들이 등장했다. 이번 장에서는 그 중 가장 유명한 BERT를 공부한다. 그의 파생 모델에는 ALBERT, RoBERTa, ELECTRA 등이 있다.
- ALBERT : A Lite BERT for Self-supervised Learning of Language Representations
- RoBERTa : A Robustly Optimized BERT Pretraining Approach
- ELECTRA : Efficiently Learning an Encoder that Classifies Token Replacements Accurately
# 17-01 NLP에서의 사전 훈련
-사전 훈련된 언어 모델의 장점: 순방향과 역방향 언어 모델을 각각 사전 훈련시킨 후, 두 가지 모두를 이용해 임베딩 값을 얻기 때문에 다의어 구분이 가능
-사전 훈련된 언어 모델을 특정 태스크에 맞추어 파인 튜닝하는 방식이 높은 성능을 얻음
-언어의 문맥은 실제로는 양방향이다. 그러나 이전 단어로부터 다음 단어를 예측하는 언어 모델의 특성으로 인해 양방향 언어 모델이 아닌 순방향+역방향을 따로 학습 방법을 사용했던 것이다.
-그러나 2018년, 입력 텍스트의 단어 집합의 15%를 랜덤으로 마스킹하는 Mased Language Model의 등장으로 양방향 구조 언어 모델이 탄생하게 된다.
# 17-02 BERT(Bidirectional Encoder Representations from Transformers)
1. BERT 개요
-BERT: 트랜스포머를 사용하여 Wikipedia, BooksCorpus와 같은 레이블이 없는 텍스트 데이터로 사전 훈련한 언어 모델
-파인 튜닝(Fine-tuning): 다른 작업에 맞추어 추가 훈련을 통해 파라미터를 재조정하는 것
ex) BERT 위에 분류를 위한 신경망을 한 층 추가하여 분류 작업에 좋은 성능을 낼 수 있음
2. BERT의 2가지 버전
-BERT-base: 연구진이 GPT-1과 성능을 비교하기 위해 일부로 같은 크기로 설계한 것
-BERT-Large: BERT의 최대 성능을 보여주는 모델, BERT가 세운 기록들은 대부분 이 버전을 사용
- L: 인코더층 개수, D: d_model 크기, A: 셀프 어텐션 헤드 수
- BERT-Base : L=12, D=768, A=12 : 110M개의 파라미터
- BERT-Large : L=24, D=1024, A=16 : 340M개의 파라미터
3. BERT의 Contextual Embedding
-BERT의 각 층에 입력된 각 단어는 모든 단어를 참고(=문맥을 반영)하여 출력된다.
-How? 각 층에서는 Multi-head Self-Attention과 FFNN이 수행된다.

4. BERT의 3가지 임베딩 층(WordPiece, Position, Segment)
아래 그림과 같이 BERT는 3개의 임베딩 층을 사용한다.
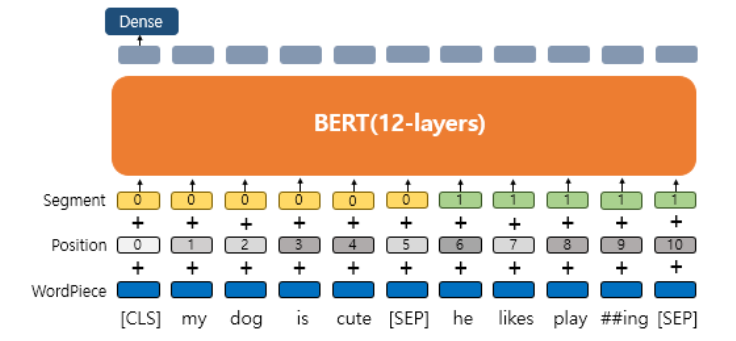
- WordPiece Embedding : 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개.
- Position Embedding : 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개.
- Segment Embedding : 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
(1) WordPiece Embedding
-WordPiece에 대한 설명은 13장 참고
-Subword Tokenizer: 토큰이 단어집합에 존재하면 그대로 사용하고, 존재하지 않으면 서브워드로 분리하여 추가
ex) embeddings가 단어 집합에 없다면 em, ##bed, ##ding, #s 로 분리. 이 때 ##은 단어의 중간에 등장한다는 것을 의미
아래는 실제로 BERT가 subword를 어떻게 분리했는지 확인 가능한 실습 코드이다.
import pandas as pd
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") # Bert-base의 토크나이저
# BERT의 단어 집합을 vocabulary.txt에 저장
with open('vocabulary.txt', 'w') as f:
for token in tokenizer.vocab.keys():
f.write(token + '\n')
# BERT의 단어 집합을 데이터프레임 형태로 불러와 확인
df = pd.read_fwf('vocabulary.txt', header=None)
df
이 때 BERT에서 사용되는 특별 토큰과 그에 매핑되는 정수들은 다음과 같다.
- [PAD] - 0
- [UNK] - 100
- [CLS] - 101 : 분류 문제를 풀기 위해 추가된 특별 토큰
- [SEP] - 102 : 문장의 끝을 의미하는 토큰
- [MASK] - 103
(2) Position Embedding
-트랜스포머의 포지셔널 인코딩: 사인함수와 코사인함수를 사용해 위치 정보를 포함한 행렬을 만들어 단어 벡터에 더함
-BERT의 포지셔널 인코딩: 위치 정보를 학습을 통해 얻음
(3) Segment Embedding
-두 문장을 구분하기 위한 임베딩 층. 첫번째 문장에는 Sentence 0, 두번째 문장에는 Sentence 1 임베딩을 더해줌
-여기서 '두 문장'이란 '두 텍스트', '두 문서', '두 문장' 등 상황에 따라 달라질 수 있음
-문장을 구분할 필요가 없는 태스크(ex. 감성분류)에서는 전체 입력에 Sentence 0 임베딩만을 더해줌
5. BERT의 2가지 사전 훈련(MLM, NSP)

-ELMo는 순방향과 역방향 LSTM을 각각 훈련시키는 구조였고, GPT는 단방향 구조였다면 BERT는 Masked LM을 통해 '양방향' 구조를 사용한다.
-BERT의 사전 훈련 방법은 두 가지 작업을 동시에 사용한다: 마스크드 언어 모델(MLM), 다음 문장 예측(NSP).
-BERT는 MLM과 NSP의 loss를 합하여 학습을 동시에 수행한다.
(1) MLM: Masked Language Model
-입력 텍스트의 15%의 단어를 랜덤으로 마스킹하고 예측시키는 작업
-이 때 선택된 15%의 단어 중 80%는 마스킹되고 10%는 랜덤으로 단어가 바뀌며 10%는 동일하게 사용한다.
ex) 아래 그림에서 'dog'는 [MASK]로 변경, 'he'는 'king'으로 변경, 'play'는 동일하게 사용되었다.

위 그림에서 'play'와 다른 단어들의 차이점은, BERT는 'play'라는 단어에 대해 원래 단어가 무엇이었을지 예측해야 한다는 점이다. 왜냐하면 BERT는 'play' 토큰을 그저 15%의 단어 중 하나로 인식할 뿐이기 때문이다.
(2) NSP: Next Sentence Prediction
-두 개의 문장을 주고 이어지는 문장인지 맞추는 방식으로 훈련시키는 작업
-이어지는 문장의 라벨은 IsNextSentence, 이어지지 않는 문장의 라벨은 NotNextSentence
-[CLS] 토큰의 위치의 출력층에서 이진 분류 문제를 풀도록 함
-이 작업이 필요한 이유: BERT가 풀고자 하는 태스크 중 Question Answering, Natural Language Inference 등 두 문장의 관계를 이해하고자 하는 태스크들이 있기 때문
6. BERT fine-tuning 하기
이제 사전훈련된 BERT를 특정 태스크에 맞추어 파인튜닝해보자.
(1) Single Text Classification

-문서의 시작에 [CLS] 토큰을 입력하고, [CLS] 토큰의 위치의 출력층에서 밀집층 혹은 완전 연결층을 추가하여 분류에 대한 예측 수행
-감성분류, 뉴스분류 등
(2) Tagging

-출력층에서 입력 텍스트의 각 토큰의 위치마다 밀집층을 사용하여 분류에 대한 예측 수행
-품사태깅, 개체명인식 등
(3) Text Pair Classification / Regression

-두 문장의 각 끝에 [SEP] 토큰을 넣고, 세그먼트 임베딩으로 문서를 구분
-자연어추론(두 문장의 관계성 분류-모순, 함의, 중립) 등
(4) Question Answering

-질문과 본문이라는 두 텍스트 쌍을 주면, '본문의 일부분을 추출해' 질문에 답변하는 태스크(대표적 데이터셋: SQuAD, Stanford Question Answering Dataset)
7. Attention Mask
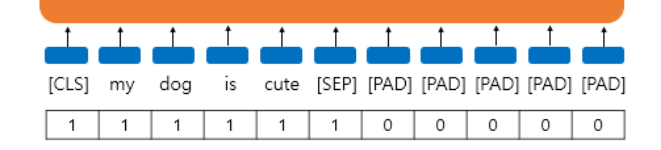
-BERT가 어텐션 연산을 할 때 패딩 토큰에 대해 어텐션하지 않도록 실제 단어와 패딩 토큰을 구분하는 작업
-실제 단어에는 숫자 1(=마스킹 수행X), 패딩 토큰에는 숫자 0(=마스킹 수행)을 할당해 BERT의 또 다른 입력으로 사용
# 17-03 영어 MLM 실습
모든 실습은 구글 코랩에서 진행한다.
# 패키지 설치
pip install transformers# 모델과 토크나이저 로드: 이 때 모델과 토크나이저는 매핑 관계여야 한다.
from transformers import TFBertForMaskedLM # BERT를 MLM 형태로 로드
from transformers import AutoTokenizer
model = TFBertForMaskedLM.from_pretrained('bert-large-uncased')
tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased")# 문장 인코딩
inputs = tokenizer('Soccer is a really fun [MASK].', return_tensors='tf')
# 정수 인코딩 결과 확인
print(inputs['input_ids'])
# 세그먼트 인코딩 결과 확인
print(inputs['token_type_ids'])
# 어텐션 마스크 확인
print(inputs['attention_mask'])# 토큰 예측하기
# FillMaskPipeline: 모델과 토크나이저를 지정해주면 모델의 예측결과를 보기 좋게 정리해 보여줌
from transformers import FillMaskPipeline
pip = FillMaskPipeline(model=model, tokenizer=tokenizer)
pip('Soccer is a really fun [MASK].') # [MASK] 위치에 들어갈 상위 5개 후보 단어 출력
# 17-04 한국어 MLM 실습
# 패키지 설치
pip install transformers# 모델과 토크나이저 로드
from transformers import TFBertForMaskedLM
from transformers import AutoTokenizer
model = TFBertForMaskedLM.from_pretrained('klue/bert-base', from_pt=True) # 대표적인 한국어 BERT
tokenizer = AutoTokenizer.from_pretrained("klue/bert-base")# 문장 인코딩
inputs = tokenizer('축구는 정말 재미있는 [MASK]다.', return_tensors='tf')
# 정수 인코딩 결과 확인
print(inputs['input_ids'])
# 세그먼트 인코딩 결과 확인
print(inputs['token_type_ids'])
# 어텐션 마스크 확인
print(inputs['attention_mask'])# 토큰 예측하기
from transformers import FillMaskPipeline
pip = FillMaskPipeline(model=model, tokenizer=tokenizer)
pip('축구는 정말 재미있는 [MASK]다.')
# 17-05 영어 NSP 실습
# 패키지 설치
pip install transformers# 모델과 토크나이저 로드
import tensorflow as tf
from transformers import TFBertForNextSentencePrediction # NSP 구조의 BERT 로드
from transformers import AutoTokenizer
model = TFBertForNextSentencePrediction.from_pretrained('bert-base-uncased')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
아래는 이어지는 문장에 대한 실습이다. 이어지지 않는 문장으로 실습하면 최종 예측 레이블이 1이 나온다.
# 이어지는 문장 2개 준비
prompt = "In Italy, pizza served in formal settings, such as at a restaurant, is presented unsliced."
next_sentence = "pizza is eaten with the use of a knife and fork. In casual settings, however, it is cut into wedges to be eaten while held in the hand."
# 문장 인코딩
encoding = tokenizer(prompt, next_sentence, return_tensors='tf')
# 정수 인코딩 결과 확인
print(encoding['input_ids']) # 이 때 101, 102는 특별 토큰
# 세그먼트 인코딩 결과 확인
print(encoding['token_type_ids'])
# 디코딩
print(tokenizer.decode(encoding['input_ids'][0]))# 다음 문장 예측
# 모델에 입력을 넣어 나온 값을
logits = model(encoding['input_ids'], token_type_ids=encoding['token_type_ids'])[0]
# 소프트맥스를 통과시켜 각 레이블에 대한 확률값 출력
softmax = tf.keras.layers.Softmax()
probs = softmax(logits)
print(probs)
# 두 값 중 더 큰 값을 예측값으로 판단
print('최종 예측 레이블 :', tf.math.argmax(probs, axis=-1).numpy()) # 최종 예측 레이블 : [0]
# 17-05 한국어 NSP 실습
# 패키지 설치
pip install transformers# 모델과 토크나이저 로드
import tensorflow as tf
from transformers import TFBertForNextSentencePrediction
from transformers import AutoTokenizer
model = TFBertForNextSentencePrediction.from_pretrained('klue/bert-base', from_pt=True) # 한국어
tokenizer = AutoTokenizer.from_pretrained("klue/bert-base")
아래는 이어지는 문장에 대한 실습이다. 이어지지 않는 문장으로 실습하면 최종 예측 레이블이 1이 나온다.
# 이어지는 문장 2개 준비
prompt = "2002년 월드컵 축구대회는 일본과 공동으로 개최되었던 세계적인 큰 잔치입니다."
next_sentence = "여행을 가보니 한국의 2002년 월드컵 축구대회의 준비는 완벽했습니다."
# 다음 문장 예측
encoding = tokenizer(prompt, next_sentence, return_tensors='tf')
logits = model(encoding['input_ids'], token_type_ids=encoding['token_type_ids'])[0]
softmax = tf.keras.layers.Softmax()
probs = softmax(logits)
print('최종 예측 레이블 :', tf.math.argmax(probs, axis=-1).numpy()) # 최종 예측 레이블 : [0]
# 17-06 센텐스버트(SBERT, Sentence BERT)
1. BERT의 문장 임베딩
BERT로부터 문장 임베딩을 얻는 3가지 방법
-[CLS] 토큰의 출력 벡터를 문장 벡터로 간주 (입력된 문장에 대한 총체적 표현)
-모든 출력 벡터들에 mean pooling (모든 단어의 의미 반영)
-모든 출력 벡터들에 max pooling ( 중요한 단어의 의미 반영)
2. SBERT
SBERT란? BERT의 문장임베딩 성능을 우수하게 개선시킨 모델
NLI 혹은 STS 태스크만으로 파인튜닝하거나, NLI 파인튜닝 후 STS 파인튜닝
(1) NLI 태스크로 파인튜닝
-NLI(Natural Language Inference): 두 문장의 관계 예측(수반/모순/중립)
-두 문장을 각각 BERT의 입력으로 넣고, 평균풀링 혹은 맥스풀링으로 각각 문장 임베딩벡터(u벡터, v벡터) 얻음
-두 벡터의 차이를 구한 |u-v|벡터, u벡터, v벡터 이 세가지 벡터를 연결(concatenation)한 h벡터 얻음
-h벡터를 출력층으로 보내 다중클래스 분류 수행
(2) STS 태스크로 파인튜닝
-STS(Semantic Textual Similarity): 두 문장의 의미적 유사성 계산
-두 문장을 각각 BERT의 입력으로 넣고, 평균풀링 혹은 맥스풀링으로 각각 문장 임베딩벡터(u벡터, v벡터) 얻음
-두 벡터의 코사인 유사도를 구함(-1에서 1 사이)
-코사인 유사도와 레이블 유사도의 MSE를 최소화하는 방식으로 학습
'딥러닝 > 딥러닝을 이용한 자연어처리 입문' 카테고리의 다른 글
| [딥러닝 NLP] 16. Transformer (1) | 2024.02.07 |
|---|---|
| [딥러닝 NLP] 15. Attention(Dot-Product Attention, Bahdanau Attention) (1) | 2024.02.06 |
| [딥러닝 NLP] 14. RNN encoder-decoder (1) | 2024.02.06 |
| [딥러닝 NLP] 13. Subword Tokenizer(BPE, SentencePiece, Huggingface) (0) | 2024.02.01 |
| [딥러닝 NLP] 12. Tagging Task 실습(NER, POS) (1) | 2024.02.01 |



